
NVIDIA 暌違 2 年之久的遊戲卡新架構「Turing」登場,一舉發表三款 GeForce 遊戲卡 RTX 2070、RX 2080 與 RTX 2080 Ti,分別使用 TU102 與 TU104 GPU,這代強化 GPC 架構下的 SM 核心,並導入 RT Core 與 Tensor Core 硬體加速核心,分別加速即時光線追蹤與深度學習運算。究竟這一代的更新,可提升多少 DirectX 11 遊戲的性能?更是玩家所重視,本篇章除創始版顯卡開箱外,更介紹這一代 Turing 架構的創新與改變,以及 AAA 大作的性能測試。
 光追、AI 遊戲未來「Turing」TU102 / TU104 / TU106 GPU
光追、AI 遊戲未來「Turing」TU102 / TU104 / TU106 GPUNVIDIA Turing 世代,不僅製程升級至 12nm FFN,架構上亦改變「Streaming Multiprocessor (SM)」設計,加入獨立的 INT 與 FP 運算單元,並提升 L1 與 L2 快取性能,讓這一代 CUDA 核心性能比起上一代有著近 50% 的性能提升。
此外,SM 單元內更加入「RT Core」與「Tensor Core」硬體加速單元,藉由專屬硬體設計,加速 Real-Time Ray Tracing 與 Deep Learning 遊戲應用,讓 GeForce RTX 遊戲顯卡走向「混合渲染」的新領域。
這一代 Turing 架構,最完整的 GPU 核心代號為「TU102」,亦是GeForce RTX 2080 Ti 與 Quadro RTX 6000 所使用的 GPU。
TU102 GPU 包含著 6 組 Graphics Processing Clusters(GPCs)與 72 組 Streaming Multiprocessors(SMs)所組成。而每一組 GPC 當中有著 6 組 TPC 單元,在每組 TPC 之下各有 2 組 SM單元。
每一組 SM 包含著 64 CUDA 核心、8 Tensor 核心、256KB 暫存器堆、4 組 Texture Units 與 96KB L1/shared Memory。
至於負責 Ray Tracing 的 RT Core,則是存在每一組 SM 單元之中;簡單來說,完整的 NVIDIA Turing 世代 TU102 有著以下幾個特點:
- 4,608 CUDA Cores
- 72 RT Cores
- 576 Tensor Cores
- 288 texture units
- 12 32-bit GDDR6 memory controllers (384-bits total)
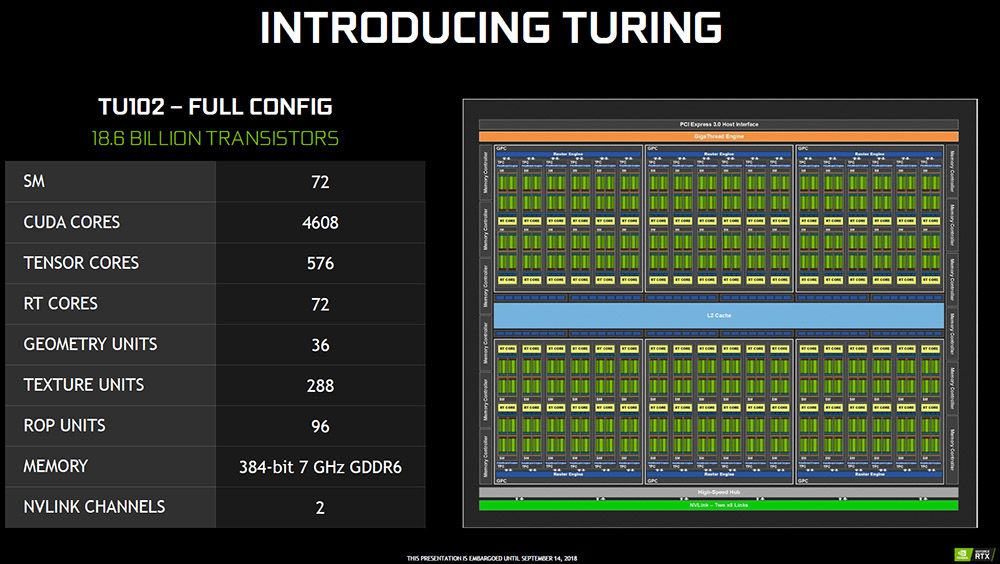
↑ NVIDIA Turing TU102 架構。
大架構來看,Turing 世代除了 12nm FFN 的製程升級,不僅提升 SM 單元性能與加速快取,更加入 RT Core 與 Tensor Core 硬體加速單元。接著細看 SM 單元內,有著共 64 組 INT32 與 64 組 FP32 核心,以及 8 組 Tensor Core、1 組 RT Core。
一組 SM 單元可分為 4 個處理區塊,每區塊有著 Warp Scheduler 與 Dispatch 單元,因此每一區塊皆可各自進行平行運算,並具備 L0 指令快取、64KB 暫存器堆;4 個處理區塊共同分享 96KB L1 Data Cache/Shared Memory。
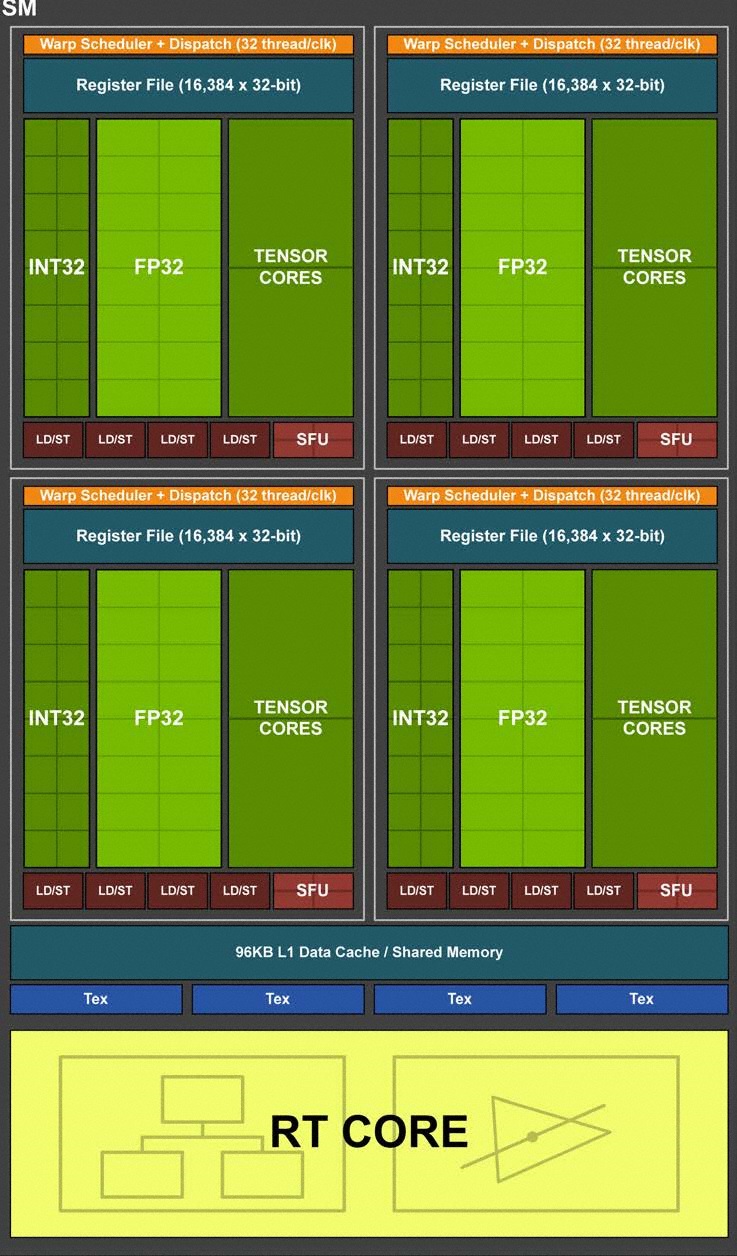
↑ SM 單元架構。
此架構設計的改變,無疑就是為了走向「混合渲染」,在一個 Turing Frame 的時間下,可分別調用 FP32 Shading、Ray Traging、INT32 Shading 與 Deep Neural Network library(DNN)混合運算,讓遊戲渲染可獲得更高的性能與運算能力,達到更為真實的遊戲體驗。
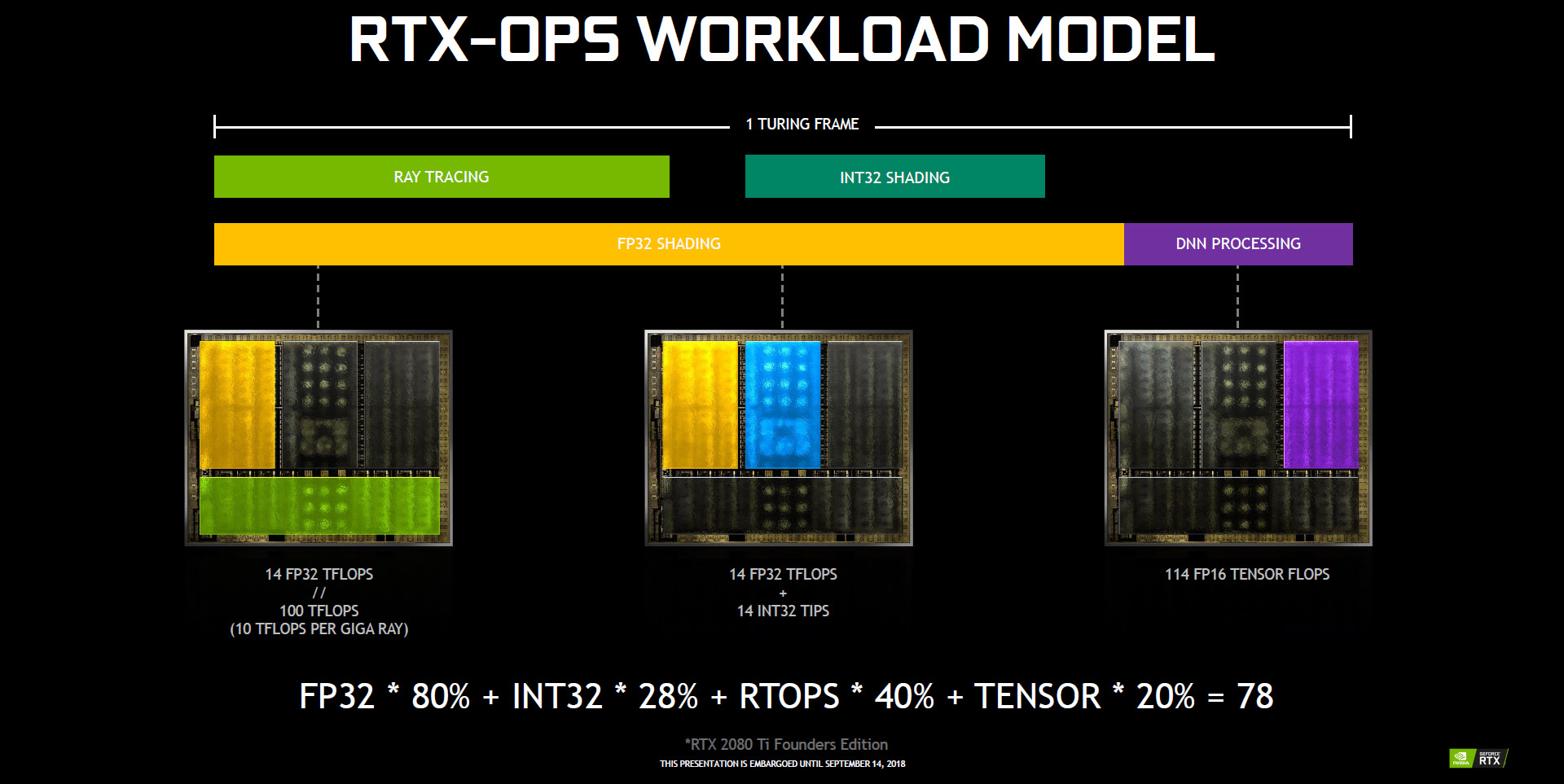
↑ Turing 所強調的混合運算能力。
But,GeForce RTX 2080 Ti 雖使用 TU102 GPU,但為了與 Quadro RTX 6000 繪圖卡區隔,因此刪減了 2 組 TPC 也就是屏蔽 4 組 SM 單元,因此 RTX 2080 Ti 的 CUDA 核心數為 4352,相對的 RT Core 與 Tensor Core 也有所不同,下表提供給各位玩家參考。
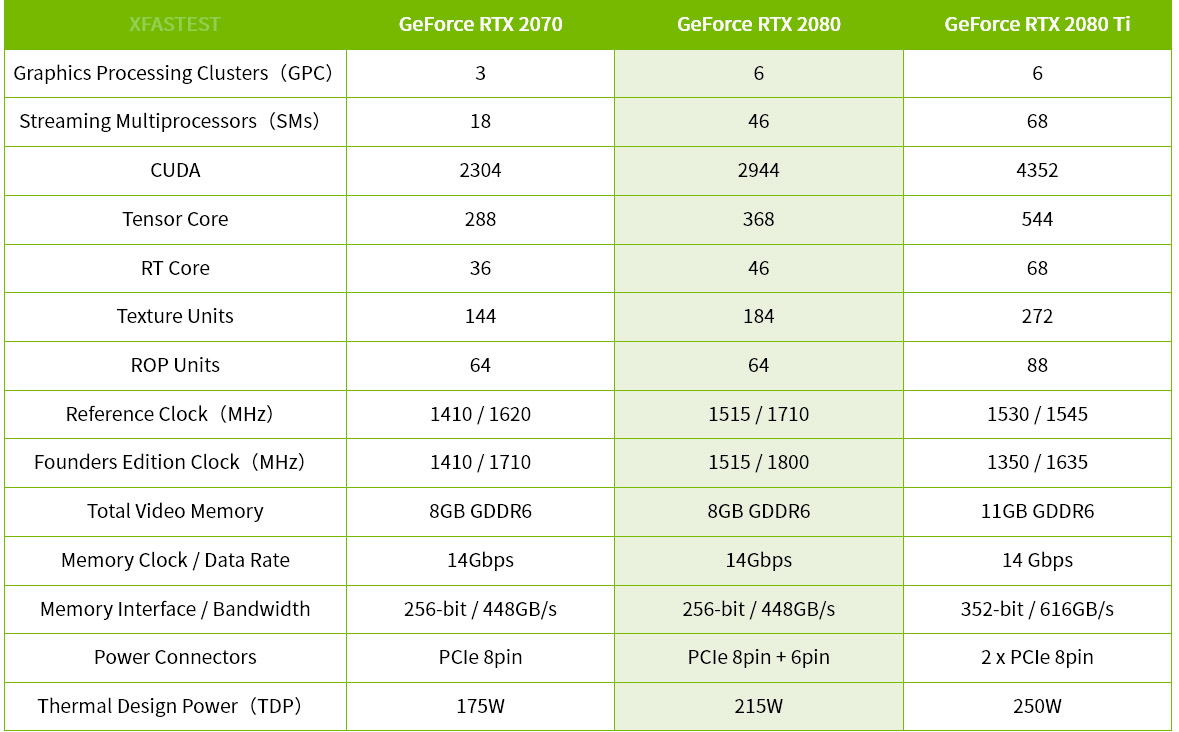
↑ RTX 2080 Ti、RTX 2080 與 RTX 2070 規格表。
而 RTX 2080 所使用的 TU104,同樣有著 6 組 GPC,但每組 GPC 之中僅有著 8 組 SM,因此共有著 2944 CUDA、368 Tensor Core、46 RT Core,並配置 8GB GDDR6 記憶體。
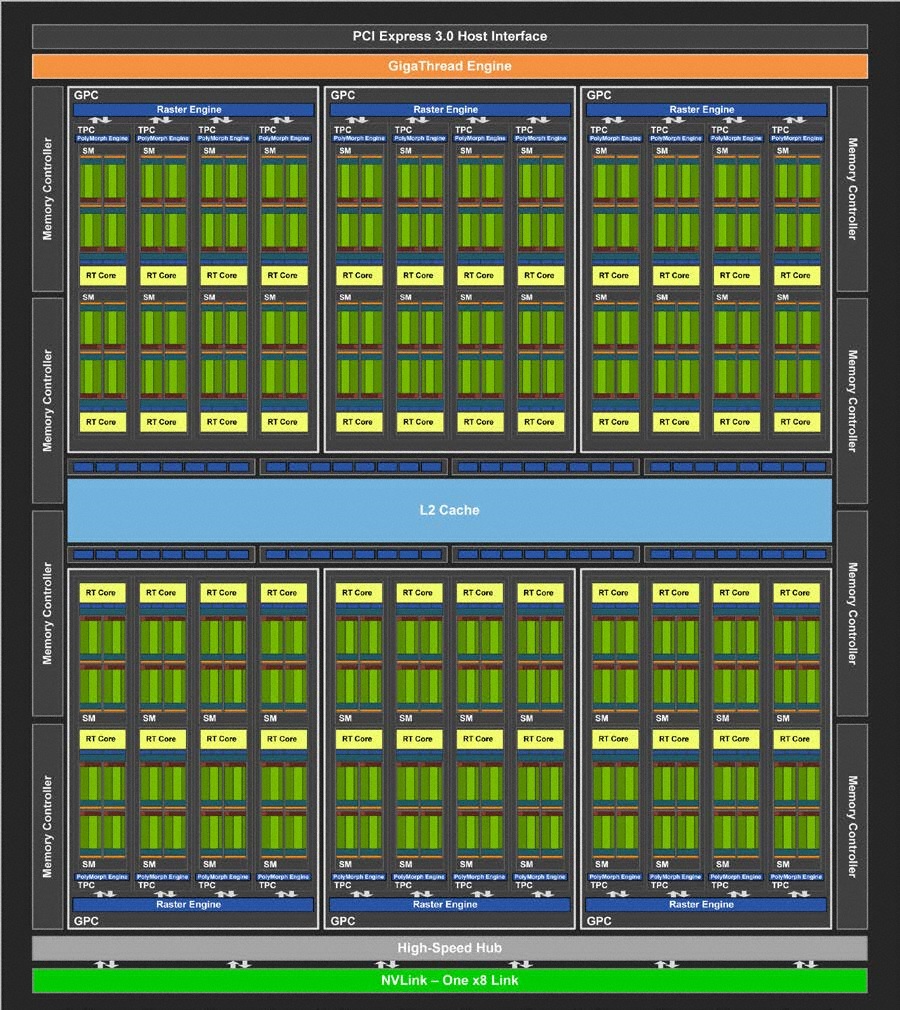
↑ TU104 架構圖。
最後 RTX 2070 使用 TU106 GPU,僅有著 3 組 GPC,而每組 GPU 維持著 12 組 SM,因此有著 2304 CUDA、288 Tensor Core、36 RT Core,同樣配置 8GB GDDR6 記憶體。

↑ TU106 架構圖。
Turing「RT Core」硬體加速 Real-Time Ray TracingReal-Time Ray Tracing 無疑是這一代的一大重點,重要到取代了 GeForce GTX 命名,新一代具備 RT Core 的產品,都以 RTX 來命名,而「光線追蹤」技術早已行之有年,但 GPU 在計算光線追蹤時,不僅效率低性能較慢,無法滿足遊戲所需的 60fps 之性能。
因此,NVIDIA 在 Turing 架構中,設計用來加速光線追蹤的「RT Core」核心,RT Core 針對「Bounding Volume Hierarchy(BVH)」演算法進行加速,將需要計算光線追蹤的物件,以 Bounding Volume 切出許多區塊,並逐步縮小 Bounding Volume,直到趨近於計算光影的位置。
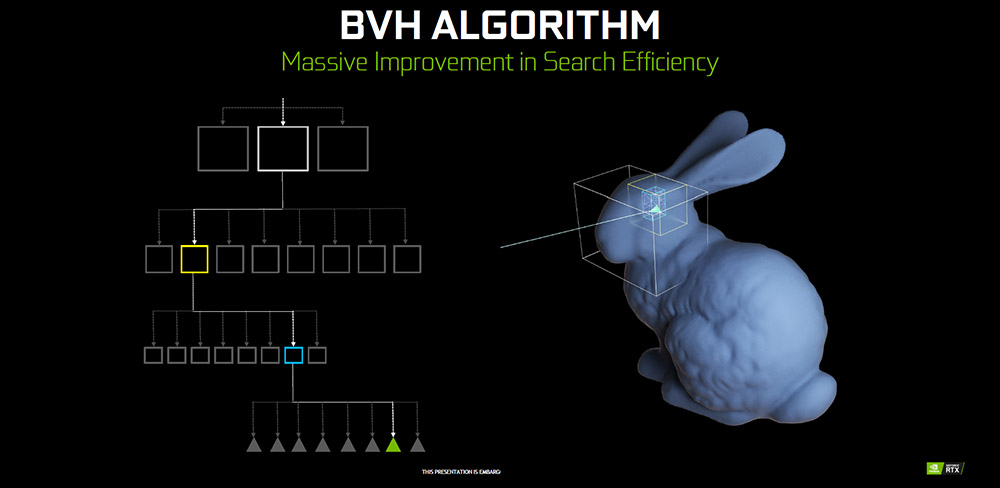
↑ Bounding Volume Hierarchy。
由於 RT Core 是獨立運算單元,因此可將光線追蹤的工作挪出主要 Shader,讓 Shader 可繼續渲染,而光線追蹤則由 RT Core 負責處理。
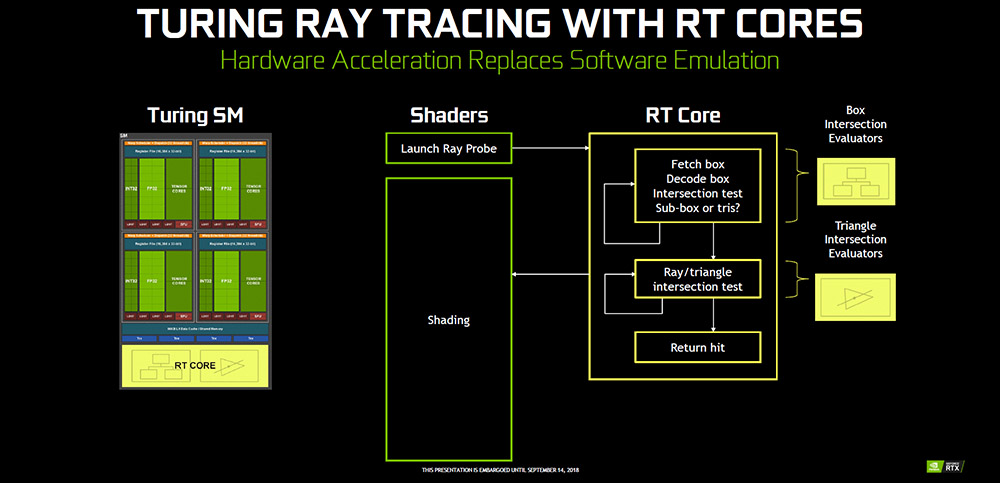
↑ RT Core 獨立運算光線追蹤。
雖然 NVIDIA 發表時提到,將來有多款遊戲支援 Real-Time Ray Tracing,但就目前測試時間點來說,作業系統與遊戲尚未支援,因此 NVIDIA 僅提供「Star Wars Reflections」展示。
筆者分別使用 RTX 2080 Ti 與 GTX 1080 Ti 來運行這 4K DLSS Star Wars Reflections 展示,在暴風兵與全身金屬反射的軍團長官搭乘電梯時,RTX 2080 Ti 運行 3840×2160 DLSS 時有著 30.85fps、32.41ms 的性能,而相較於 GTX 1080 Ti 則只能跑 2560×1440 解析度時 7.74fps、129.20ms 的性能。
由此可見,具備 RT Core 與 Tensor Core 的新一代 RTX-20 系列顯示卡,可給予玩家更強悍的混合運算性能。(原圖下載)

↑ RTX 2080 Ti 運行 3840×2160 DLSS 性能 30.85fps、32.41ms。

↑ GTX 1080 Ti 運行 2560×1440性能 7.74fps、129.20ms。
Turing「Tensor Core」硬體加速 Deep Learning 遊戲應用Deep Learning 深度運算是目前最接近 AI 人工智慧的技術,亦是目前 NVIDIA 相當重視的 GPU 應用領域。
Turing 隨著 Volta GV100 的腳步,於 GPU 內加入「Tensor Core」核心,並支援 INT8、INT4 與 FP16 等不同精度的計算。
Tensor Core 核心以硬體方式加速深度學習,在訓練(Training) Neural Network 與推理(Inferencing)時所需要的 Matrix Multiplication 計算。

↑ 獨立的 Tensor Core 核心可更快速運算 Neural Network 的推理。
當然 NVIDIA 並非只設計硬體,針對 Deep Learning 的技術應用,NVIDIA 提供一套 NGX(Neural Graphics Acceleration)技術,由 NVIDIA 自行訓練的 Deep Neural Networks(DNNs),可利用 AI 來加速繪圖、渲染等應用。
遊戲開發商或開發者,可運用 NVIDIA NGX 所提供的 API,像是 AI Super REZ、AI SLOW-MO、AI INPAINTING 與 NVIDIA DLSS 等功能應用,都可透過 NVIDIA GeForce Experience 進行更新與調用。

↑ AI INPAINTING 即是智慧影像填補,可將圖中的雜物、路人刪去,並由 AI 來計算填補的影像。
↑ AI SLOW-MO 即是讓一般 60fps 的影片,藉由 AI 來補幀達到 240fps、480fps 的慢動作影片。

↑ AI Super REZ 則透過 AI 來強化影像畫質。
其中 NVIDIA 主打的 Deep Learning 遊戲應用莫過於「DLSS(Deep Learning Super-Sampling)」,藉由深度學習的方式,讓 AI 來自動計算遊戲的超級採樣反鋸齒技術。
換句話說,以往遊戲渲染的影像,通過 Temporal Anti-Aliasing(TAA)計算影像反鋸齒,最終可獲得邊緣平順的高質感影像,但也大幅佔用 GPU 資源,使得遊戲性能的下降。
而 DLSS 的遊戲開發相當特別,遊戲廠商需將遊戲世界的素材、影像,以及高質量的反鋸齒素材,交給 NVIDIA 的超級電腦,由 NVIDIA 來訓練 Deep Neural Network(DNN),當遊戲開發(訓練)完成後,玩家在執行遊戲時則將反鋸齒交由 Tensor Core 處理驗證,如此一來可獲得更好的遊戲性能,以及出色的反鋸齒畫質。
只不過,目前支援 DLSS 的遊戲尚未更新,NVIDIA 則提供「Final Fantasy XV Benchmark」測試。
當遊戲運行在 3840×2160 的 4K 解析度時,倘若一般 TAA 反鋸齒技術,會讓整體性能壓在不到 60fps,但藉由 DLSS 進行超採樣反鋸齒時,不僅可讓性能得以提升,並得到近似於 TAA 反鋸齒的效果。
但若放大仔細看會發現,DLSS 有些地方計算的比 TAA 好,但有些地方因為 DLSS 訓練的素材不足,導致結果比 TAA 模糊的問題。
這也可印證,DLSS 可以獲得更好的性能,但整體的畫質取決於前期的 Deep Neural Network(DNN)訓練素材是否足夠。(原圖下載)
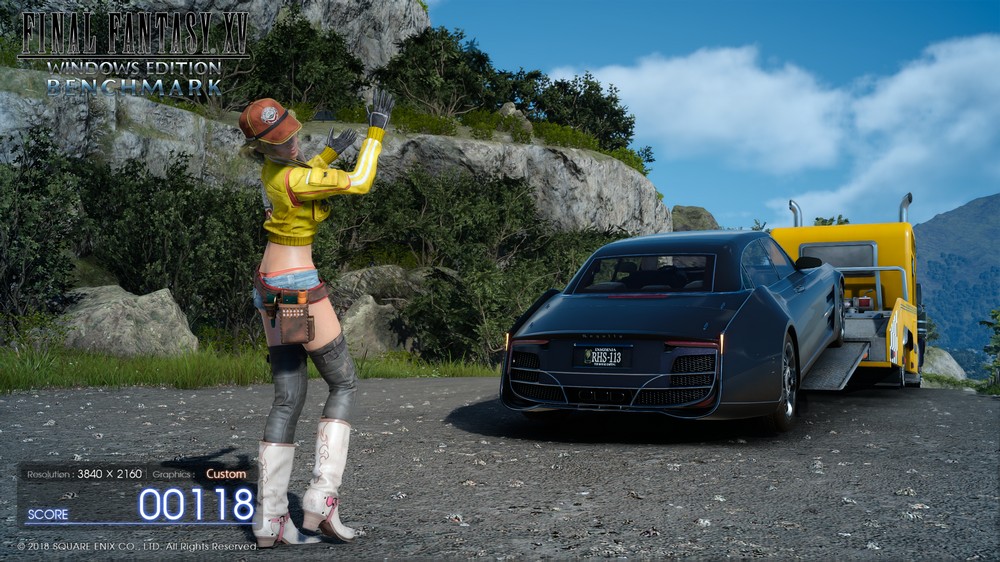
↑ Final Fantasy XV Benchmark DLSS 與 TAA 比較圖。

↑ DLSS 於丁子褲的帶子上,有著相當好的反鋸齒效果。

↑ TAA 在丁子褲的帶子上,則有著鋸齒狀。

↑ DLSS 在車牌驗證上,由於文字是單一且獨特,若沒訓練車牌或文字的 DNN,所以車牌下方的文字相當模糊。

↑ TAA 在車牌計算上則相對清楚。
進階繪圖 Mesh Shading、Variable Rate Shading (VRS)這一代的更新 NVIDIA 加入相當多的功能,都為了提升整體的繪圖效能,就像是「Mesh Shading」。當遊戲世界的「物件」數提升時,很容易導致 GPU 性能的下降,這在 MMO 或打寶遊戲常遇到,物件、敵人、玩家擠在同一個區域時,很容易造成性能的驟降。
因此 NVIDIA 提出的「Mesh Shading」,不像以往物件由 CPU 遞交 Draw Call 給 GPU 的方式,Mesh Shading 可讓開發者將物件清單交給 GPU 平行運算,並由 Mesh Shader 依據物件不同的 Levels of Detail(LOD)等級進行細節的渲染。
從 NVIDIA 提供的 Asteroids Demo 展示,畫面中有著數以萬計的小行星,若每一個都用最高 LOD 進行渲染,則會導致效能不足,且距離遊戲視窗越遠的物件,其實難以分辨其細節,因此透過 Mesh Shading 針對不同 LOD 的物件進行渲染,即可兼顧畫質與性能的平衡。

↑ Asteroids Demo 3840×2160,畫面中有著 27 萬顆小行星,透過動態 LOD 給予不同的細節等級,畫面中黑色是細節最高,如此一來可讓畫面豐富但亦保有性能。
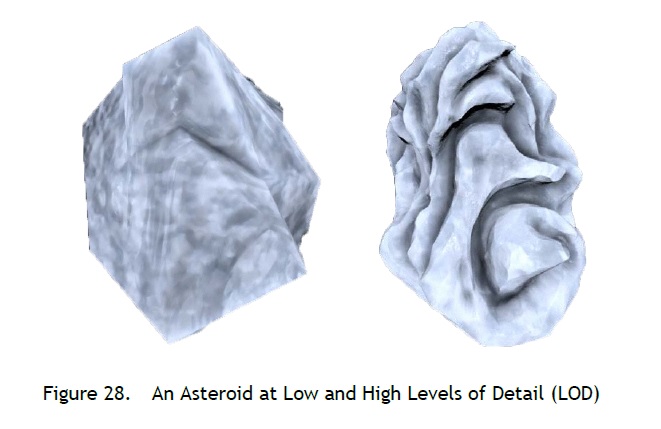
↑ 不同的物件 LOD 決定物件最終的細節。
而「Variable Rate Shading」則可讓開發者依據不同的層級來進行影像的渲染,例如賽車遊戲畫面中,賽車的車身、遠景,必須要豐富的細節採用 1×1 來渲染,而因為動態模糊關係,使得馬路、四周景物較難分辨細節,則可採用 2×2、4×4 的方式來進行渲染。
這渲染方式亦可讓遊戲有更好的性能,更可應用在 Content Adaptive Shading、Motion Adaptive Shading、Foveated Rendering 等情境。

↑ Variable Rate Shading。
8K30 編碼 HEVC 支援與 VirtualLinkNVIDIA GeForce RTX-20 系列,支援 8K60 HDR 的影像輸出,以及 VirtualLink Type C 介面。單一組 VirtualLink 介面,及包含著:4 lanes HBR3 DisplayPort 影音輸出、USB 3.1 Gen2 SuperSpeed 資料傳輸、27W 電源供電。
也就是說 1 組 VirtualLink C,即可用來連接 VR 頭盔所需的影像、資料與供電,讓 VR 體驗更便利;而且未來螢幕亦可以 Type C 方式來連接影像與供電。

↑ 8K60 HDR 輸出與 VirtualLink。
影像編解碼方面,則支援 HEVC 8K30 HDR 即時編碼、HEVC 與 H.264 編碼的性能提升,解碼則支援 VP9 10/12b HDR 與 HEVC 444 10/12b HDR。
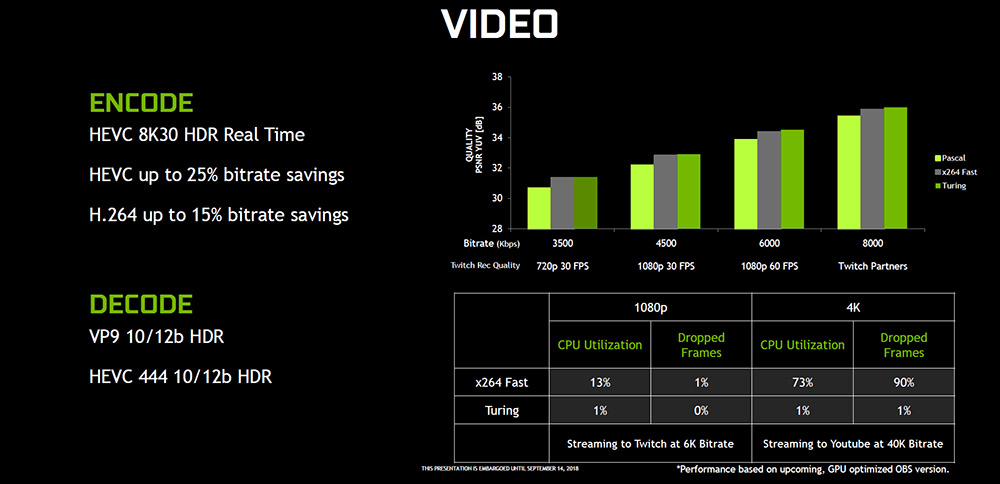
↑ 影音編碼支援。
創始版 NVIDIA GeForce RTX 2080 與 RTX 2080 Ti 超頻顯示卡開箱首波開箱的 NVIDIA GeForce RTX 2080 與 RTX 2080 Ti 創始版,這代賣的不僅只是信仰,更是已經超頻後的性能,這也是 NVIDIA 少見採用雙扇、均熱板散熱設計,因此顯卡厚度維持在 2 slot,但 GPU 時脈已預先超頻。
詳細的規格不再贅述,創始版規格主要在超頻時脈與 TDP 比標準高,其餘規格則相同。
這代顯示卡外盒有著相當漂亮的彩盒,打開後顯卡則立於盒內,並寫著:「INSPIRED BY GAMERS. BULIT BY NVIDIA.」。
顯示卡配件盒中,則有著兩本說明與支援文件,以及一條 DisplayPort 轉 DVI 線材。

↑ 創始版 NVIDIA GeForce RTX 2080 與 RTX 2080 Ti 外箱。

↑ 採用直立顯卡的包裝設計。

↑ INSPIRED BY GAMERS. BULIT BY NVIDIA.。

↑ 配件盒。
這代外觀上不像 GTX-10 系列那麼多的立體三角造型,而是簡潔俐落的點線面,對稱呼應著雙扇的設計,亦因為主推 Ray Tracing 的關係,創始版外觀的金屬材質,依據不同的光線呈現出不同的面貌。

↑ RTX 2080 與 RTX 2080 Ti 創始版。

↑ 對稱的雙扇設計,以及高質感的金屬外殼。
顯示卡上方側面與下方有著對稱設計,上側中央有著 GEFORCE RTX 字樣,為開機時是濺鍍的鏡面,而開機後則會亮起 NVIDIA 的信仰綠燈。
RTX 2080 創始版採用 6+8pin 供電,而 RTX 2080 Ti 則是 8+8pin 供電設計。

↑ 側面有著 GEFORCE RTX 字樣。

↑ RTX 2080 6+8pin、RTX 2080 Ti 8+8pin。
顯卡的 NVLink 金手指,有著專屬的防塵蓋,若要使用 NVLink 橋接器,僅需將蓋子移除即可安裝。

↑ NVLink 金手指與防塵蓋。

↑ 顯卡下方側面也有著對稱設計。

↑ 顯卡前端則有 NVIDIA 的 Logo。

↑ 顯卡背面則是銀色背板。
創始版維持著標準卡的長與寬,顯卡長度維持在 27cm,厚度則是保持在 2 slot 約 4cm 的厚度。
創始版亦是目前少數超頻卡,能夠保持在標準 2 slot 厚度內的設計,這也意味著新版散熱,在厚度不變改為雙扇設計下,即可帶來更好的散熱性能。

↑ 顯卡長度 27cm。

↑ 顯卡厚度 2 slot、4cm 左右。
顯示輸出,創始版則提供 1 組 VirtualLink C、3 組 DisplayPort 1.4a 與 1 組 HDMI 2.0b HDCP 2.2。
因此最高可達到 DisplayPort 8K60Hz 輸出,而 HDMI 最高 4K60Hz 輸出。

↑ 顯示卡輸出介面。
創始版的拆解老實說:「螺絲、銅柱非常的多。」,也因此整體顯卡的結構強度相當高。拆除散熱器之後,即可見到 RTX 2080 的 GPU。
RTX 2080 採用 TU104-400A-A1 GPU,並配置 8 顆 Micron GDDR6 記憶體,供電則採用 8+2 相 iMON DrMOS 設計,GPU 8 相、記憶體 2 相。

↑ RTX 2080 創始版拆解,散熱器、電路板與金屬背板。

↑ TU104-400A-A1 GPU。

↑ 10 相供電設計。

↑ RTX 2080 電路板背面。
RTX 2080 Ti 創始版設計相同,只不過 TU102-300A-K1-A1 GPU 面積比起 TU104 還要大上許多,周圍則配置 11 顆 Micron GDDR6 記憶體,並採用 13+3 相 iMON DrMOS 供電設計,GPU 13 相、記憶體 3 相。

↑ RTX 2080 Ti 創始版拆解。

↑ TU102-300A-K1-A1 GPU。

↑ 左側的 6 相供電。

↑ 右側 10 相供電。

↑ RTX 2080 Ti 電路板背面。
創始版的 RTX 2080 與 RTX 2080 Ti 開機後,上方側面的 GEFORCE RTX 會亮起綠色信仰燈,讓玩家可感受 NVIDIA 的魅力。

↑ 信仰燈 GEFORCE RTX。
GPU BOOST 4.0 與 NVIDIA SCANNER自 NVIDIA GTX-10 代以來,GPU 只要在更低的溫度與更多功耗的情況下,可藉由 GPU Boost 3.0自動超頻,讓 GPU 時脈超過規格的 Boost 時脈。
GPU Boost 3.0 的運作猶如下圖所示,在電源與溫度的限制下,盡可能的提高時脈。
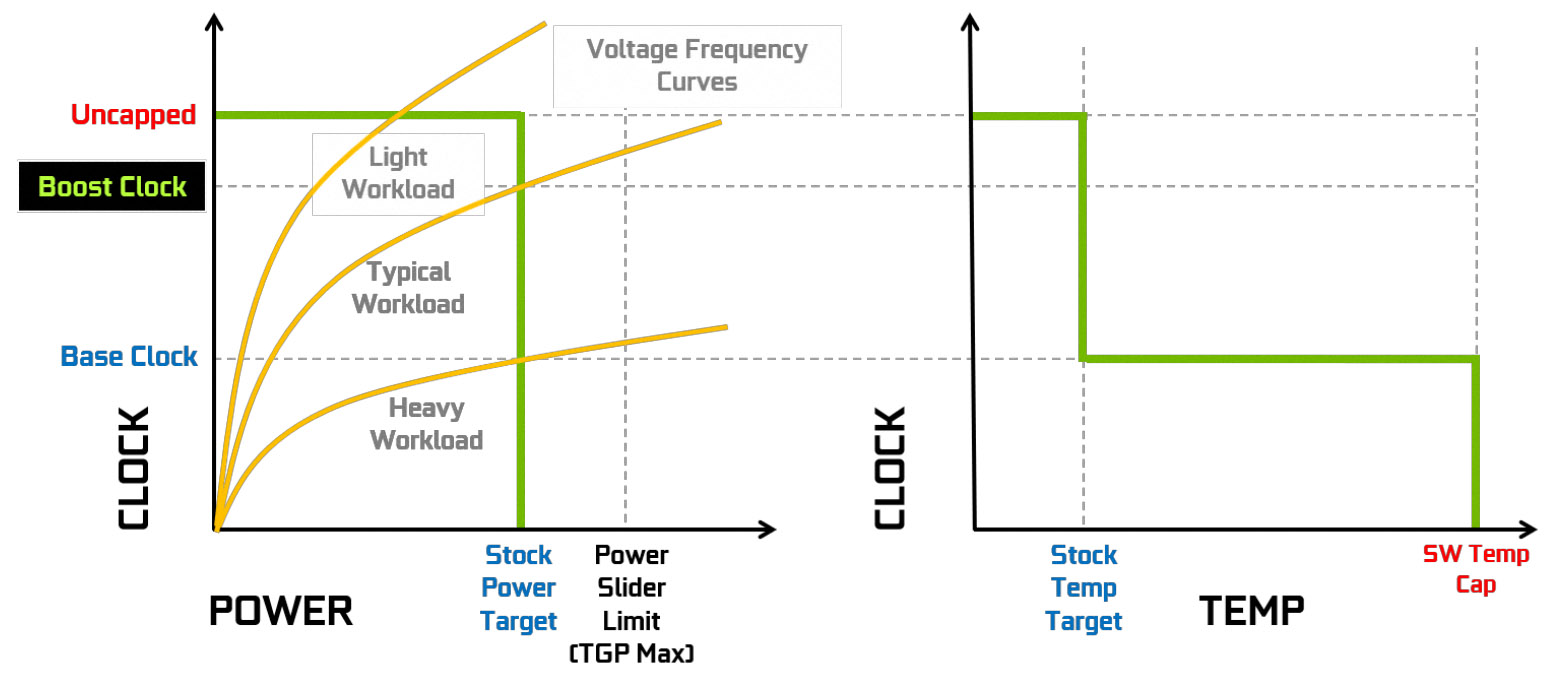
↑ GPU Boost 3.0。
至於 GPU Boost 4.0 則允許玩家自行控制溫度的節點,也就是說玩家可透過軟體,如 EVGA PrecisionX1 或 MSI Afterburner 軟體來控制,調整 GPU Boost 4.0 的溫度節點,例如將節點全部拉到 T2 溫度點,即可獲得更高的性能,但相對的 GPU 溫度也會跟著提升。
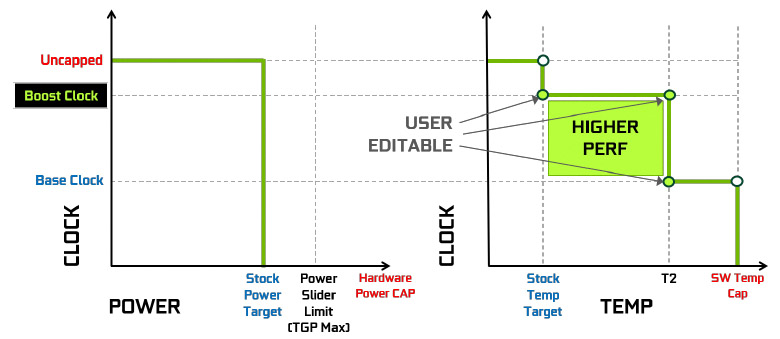
↑ GPU Boost 4.0 玩家可透過軟體調整自動超頻的溫度節點。
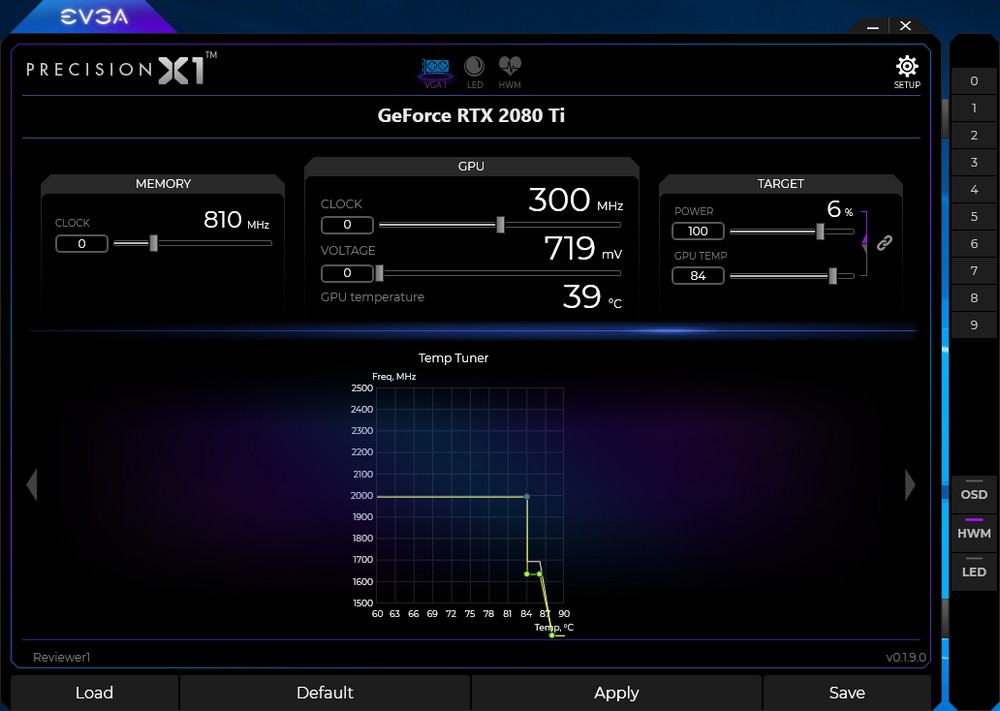
↑ 透過 PrecisionX1 軟體調整溫度控制點。
此外,NVIDIA 可量到並非所有玩家都熟悉顯示卡的超頻,因此推出 NVIDIA Scanner 功能,玩家在掃描前可先調整 Power Target 與 GPU Temp Target,而 Scanner 會依據不同的 GPU 電壓,來測試 GPU 時脈與溫度的表現,讓玩家在簡易調整電源目標與溫度目標後,確保顯卡能穩定運作。
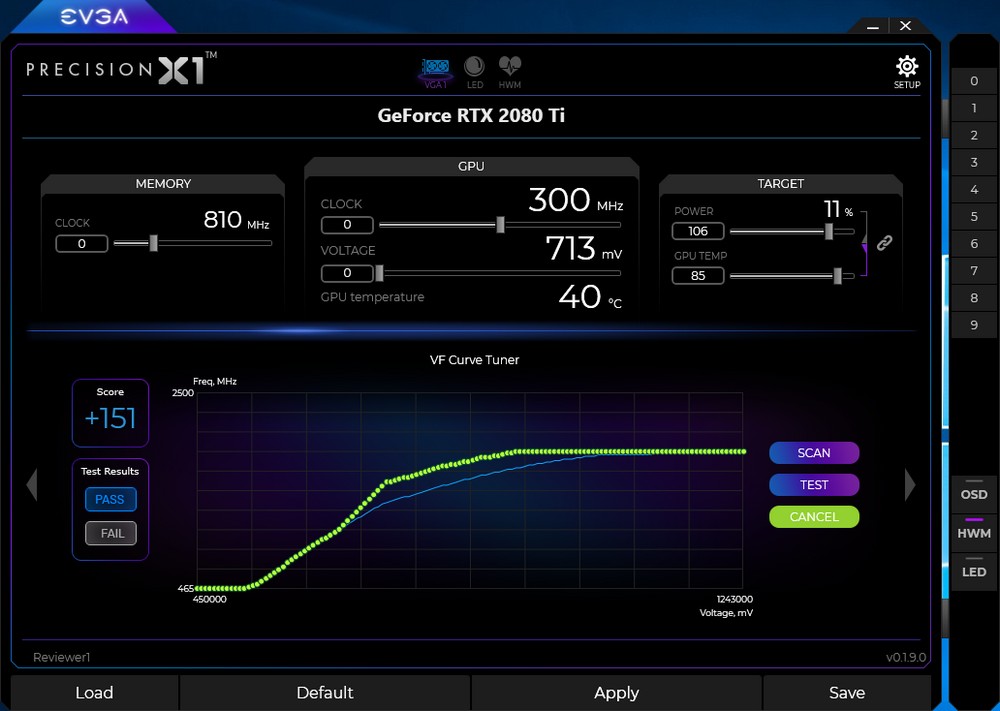
↑ NVIDIA Scanner 功能,調整 Power Target 與 GPU Temp Target 後,透過 Scanner 進行不同電壓下的時脈測試。
GeForce RTX 2080 與 RTX 2080 Ti 性能測試這一代 Turing 加入許多新遊戲功能,但現階段主流 AAA 遊戲還是以 DirectX 11 為大宗,而 DirectX 12 或 Vulkan API 則相對少,因此不少玩家好奇這一代 RTX 2080 與 RTX 2080 Ti,比起上一代 GTX 1080 與 GTX 1080 Ti 的性能有多少提升?
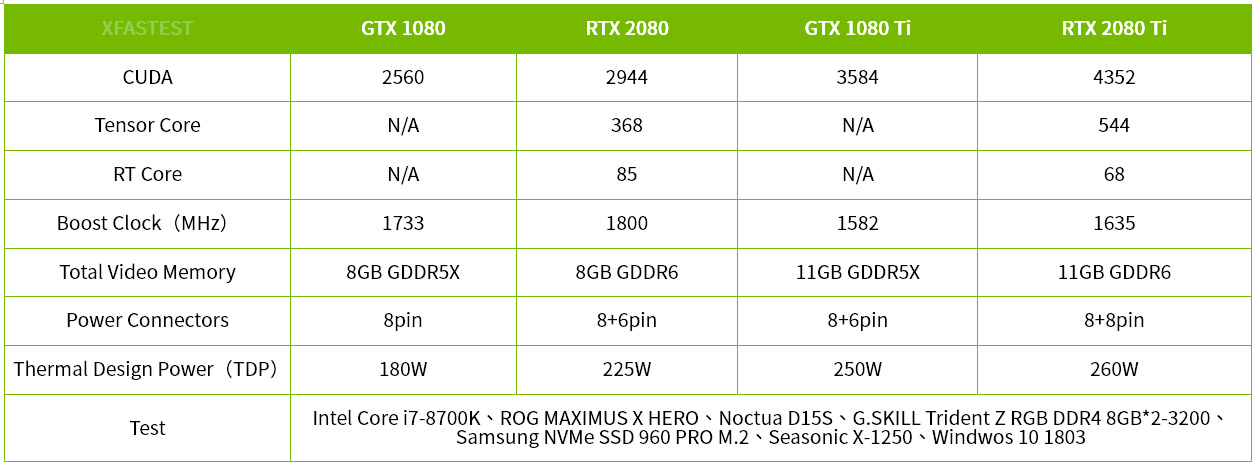
↑ 本次測試平台規格。
GeForce RTX 2080 與 RTX 2080 Ti 功耗測試這一代創始版,不僅摒棄單鼓風扇設計,改以雙扇與大面積均熱板散熱器,讓 RTX 2080 與 RTX 2080 Ti 創始版出廠已超頻,這一代創始版不僅象徵著 NVIDIA 信仰,更強調創始版是有足夠的性能,而非用來比較性能的基準。
RTX 2080 與 RTX 2080 Ti 待機時,GPU 溫度僅 35°C、40°C,通過 Fire Strike Stress test 與 FurMark 1080p, 4XMASS 進行測試,RTX 2080 GPU 溫度來到 74°C、RTX 2080 Ti GPU 溫度 78°C,比起上一代飆至 82°C 的溫度來看,確實這代散熱有更好的性能,況且即便燒機下風扇也相當安靜。
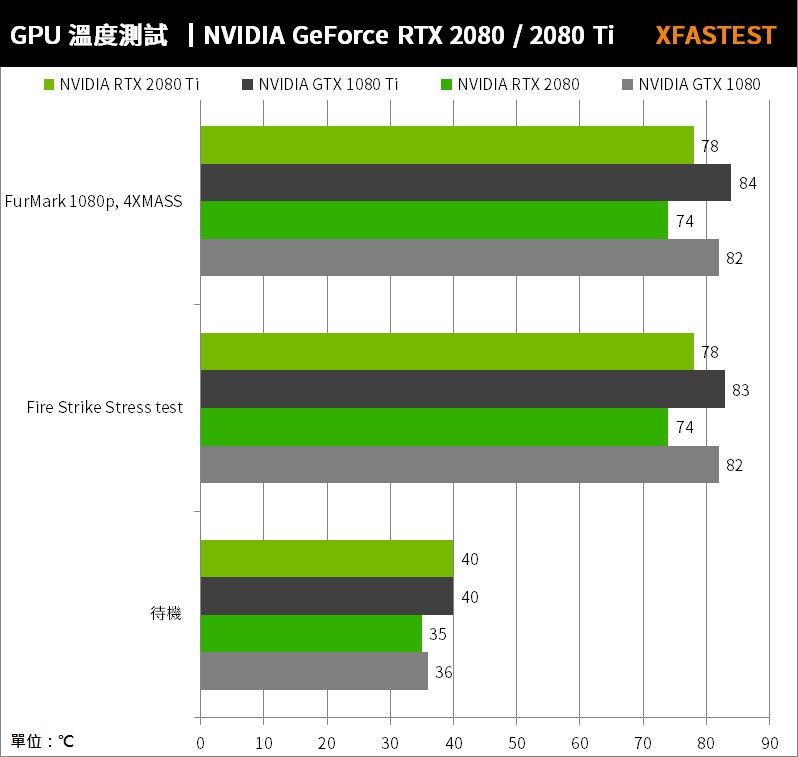
↑ GPU 溫度測試,越低越好。
功耗方面,待機時 RTX 2080 與 RTX 2080 Ti 整機功耗約在 90W 左右,而壓力測試下 Fire Strike Stress test 整機功耗來到 RTX 2080 / 343W、RTX 2080 Ti / 395W;至於 FurMark 最高功耗則在 330W、355W。
由於 Fire Strike Stress test 的 CPU 使用率比 FurMark 高的關係,在 Intel Core i7-8700K 的平台上測試,這功耗差異是可預期。由於核心數的提升與高時脈,讓 RTX-20 系列的功耗在往上提升,但也對的起他的效能。
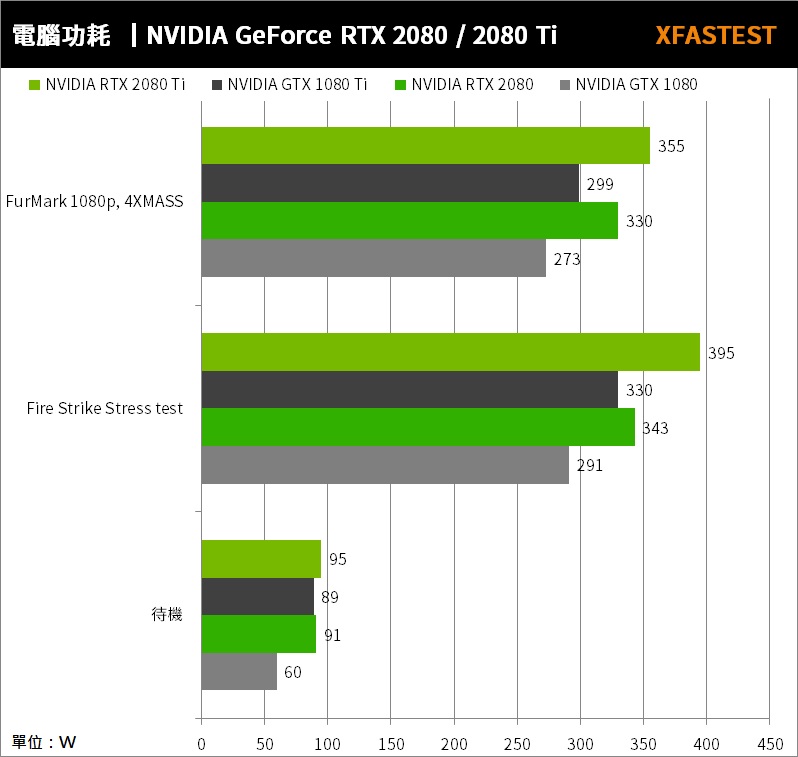
↑ 整機功耗測試。
總結新一代 GeForce RTX 2080 與 RTX 2080 Ti,不僅改變核心 SM 設計,加入獨立的 INT 與 FP 運算單元,以及 RT Core 與 Tensor Core 硬體加速單元,讓這一代更符合混合渲染、運算需求,給予玩家更強悍的次世代性能。
這代 GPU 不僅製程提升、CUDA 核心在往上推疊,更具備光線追蹤 RT Core 與深度學習 Tensor Core,面對即時光追、DLSS 等應用,這代性能更遠高於上一代,只不過目前測試時,宣布支援的遊戲皆未準備好,因此無法在這時間點,就對這一代 GPU 做出結論。

↑ 這不就是玩家期待的遊戲光線嗎?
NVIDIA 無疑是希望用硬體、用技術,推動遊戲產業走向更先進的渲染技術,這代 RTX-20 賣點不外乎即是「4K60」與「遊戲未來」。
就 4K60 這點 RTX 2080 Ti 算是在主流 DirectX 11 大作遊戲測試下算是及格了;但就 RTX 2080 來說還是有點勉強,而 RTX 2080 更適合 1440p、1080p 解析度下特效全開。
至於遊戲未來,不外乎更逼真的光線追蹤、照明與陰影的呈現,以及運用 Deep Neural Network(DNN) 訓練 DLSS、慢動作補幀、高解析度等技術,未來遊戲就像電影一樣,各位在腦中試想想:「我們再操控蘿拉·卡芙特進行探險時,可以在驚險、刺激的場面時,透過 AI SLOW-MO 來即時 480fps 慢動作的過場畫面。」。
皆下來就期待支援 Ray Tracing、DLSS 技術的遊戲推出,我們在來測一遍 RTX-20 系列的遊戲未來性能;而這一代創始版,採用新的散熱設計與出廠超頻,不外乎是要讓玩家知曉:「朕賣的不只是信仰,更是技術標竿。」。

↑ 千萬別在等電梯的時候 Small talk 阿!
至於價格方面,RTX 2080 創始版 $799 美金、RTX 2080 Ti 創始版來到 $1,199 美金,確實比上一代 GTX-10 系列剛發表的價格高了許多,但這也是性能、技術堆疊下的必然。(若性能提升賣一樣的價錢不就是 NVIDIA 慈善佛堂了嗎!)。
若各位玩家追的是 4K60,那 RTX 2080 Ti 毋庸置疑,若各為期待的是未來遊戲技術,做為務實玩家,可以留待大作遊戲推出之時,在來決定是否要升級,畢竟 GTX-10 系列性能,還是可滿足大部分 1080p 的玩家需求。

↑ NVIDIA GeForce RTX-20 系列價格與時程(2080 Ti 出貨會延一個禮拜)。
4K60 心願已了,接著光追、AI 遊戲未來,NVIDIA 再次提升遊戲顯卡效能,更追逐遊戲未來新技術,這一代不僅只是信仰更是你對未來的投資。
沒有留言:
張貼留言